本文主要记录了如何将 etcd 集群接入到 Prometheus 监控系统
按照本文操作,你可以使用 Prometheus 来监控你的 etcd 集群。
etcd 作为元数据存储,生产环境建议都配置上监控。
k8s 集群里的 etcd,或者外置 etcd 都可以进行监控。
大致分为三个部分:
- 1)配置 Targetr, 让 Prometheus 采集 etcd 指标
- 2)配置 Grafana 模板
- 3)配置告警规则
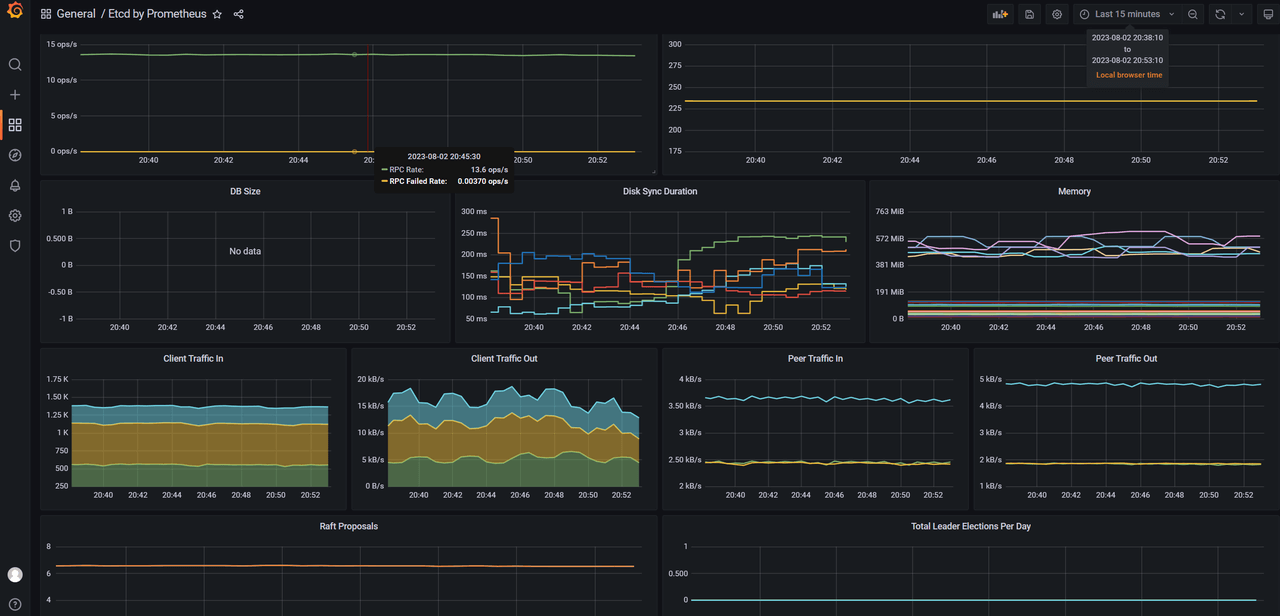
最终效果:
推荐使用 prometheus-operator 进行部署,具体见官方文档。
1. 了解 Etcd metrics
官方文档:Metrics
etcd 默认会在 2379 端口上暴露 metrics,例如: https://192.168.10.41:2379/metrics。
先用 curl 命令检测一下,是否正常。
1
| curl http://192.168.10.41:2379/metrics
|
对于开启 tls 的 etcd 集群,则需要指定客户端证书,例如
1
2
| certs=/etc/kubernetes/pki/etcd/
curl --cacert $certs/ca.crt --cert $certs/peer.crt --key $certs/peer.key https://192.168.10.55:2379/metrics
|
Etcd 中的指标可以分为三大类:
Server
以下指标前缀为 etcd_server_。
- has_leader:集群是否存在 Leader
- leader_changes_seen_total:leader 切换数
- proposals_committed_total:已提交提案数
- 如果 member 和 leader 差距较大,说明 member 可能有问题,比如运行比较慢
- proposals_applied_total:已 apply 的提案数
- 已提交提案数和已 apply 提案数差值应该比较小,持续升高则说明 etcd 负载较高
- proposals_pending:等待提交的提案数
- 该值升高说明 etcd 负载较高或者 member 无法提交提案
- proposals_failed_total:失败的提案数
1
| -e leader_changes_seen_total -e proposals_committed_total -e proposals_applied_total -e proposals_pending
|
Disk
以下指标前缀为 etcd_disk_。
- wal_fsync_duration_seconds_bucket:反映系统执行 fdatasync 系统调用耗时
- backend_commit_duration_seconds_bucket:提交耗时
Network
以下指标前缀为etcd_network_。
- peer_sent_bytes_total:发送到其他 member 的字节数
- peer_received_bytes_total:从其他 member 收到的字节数
- peer_sent_failures_total: 发送失败数
- peer_received_failures_total:接收失败数
- peer_round_trip_time_seconds:节点间的 RTT
- client_grpc_sent_bytes_total:发送给客户端的字节数
- client_grpc_received_bytes_total:从客户端收到的字节数
核心指标
上面就是 etcd 的所有指标了,其中比较核心的是下面这几个:
etcd_server_has_leader:etcd 集群是否存在 leader,为 0 则表示不存在 leader,整个集群不可用etcd_server_leader_changes_seen_total: etcd 集群累计 leader 切换次数etcd_disk_wal_fsync_duration_seconds_bucket:wal fsync 调用耗时,正常应该低于 10msetcd_disk_backend_commit_duration_seconds_bucket:db fsync 调用耗时,正常应该低于 120msetcd_network_peer_round_trip_time_seconds_bucket:节点间 RTT 时间
2. 配置 etcd 监控
创建 etcd service & endpoint
对于外置的 etcd 集群,或者以静态 pod 方式启动的 etcd 集群,都不会在 k8s 里创建 service,而 Prometheus 需要根据 service + endpoint 来抓取,因此需要手动创建。
注意:将 endpoint 中的 IP 替换为真实 IP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| cat > etcd-svc-ep.yaml << EOF
apiVersion: v1
kind: Endpoints
metadata:
labels:
app: etcd-prom
name: etcd-prom
namespace: kube-system
subsets:
- addresses:
# etcd 节点 ip
- ip: 192.168.10.41
- ip: 192.168.10.55
- ip: 192.168.10.83
ports:
- name: https-metrics
port: 2379 # etcd 端口
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
labels:
app: etcd-prom
name: etcd-prom
namespace: kube-system
spec:
ports:
# 记住这个 port-name,后续会用到
- name: https-metrics
port: 2379
protocol: TCP
targetPort: 2379
type: ClusterIP
EOF
|
apply 到集群里
1
| kubectl apply -f etcd-svc-ep.yaml
|
创建 secret 存储证书
将访问 etcd 集群的证书写入 secret,后续挂载到 prometheus pod 以访问 etcd。
注意:替换为真实的证书路径
1
2
| certs=/etc/kubernetes/pki/etcd/
kubectl -n monitoring create secret generic etcd-ssl --from-file=ca=$certs/ca.crt --from-file=cert=$certs/peer.crt --from-file=key=$certs/peer.key
|
需要将 secret 写入 prometheus 同一 namespace,默认为 monitoring。
将证书挂载至 Prometheus 容器
由于 Prometheus 是 operator 方式部署的,所以只需要修改 prometheus 对象即可,operator 会自动处理。
1
| kubectl -n monitoring edit prometheus k8s
|
然后添加以下内容,在 Prometheus 对象里新增 secrets 字段,并指定为上一步创建的 secret。
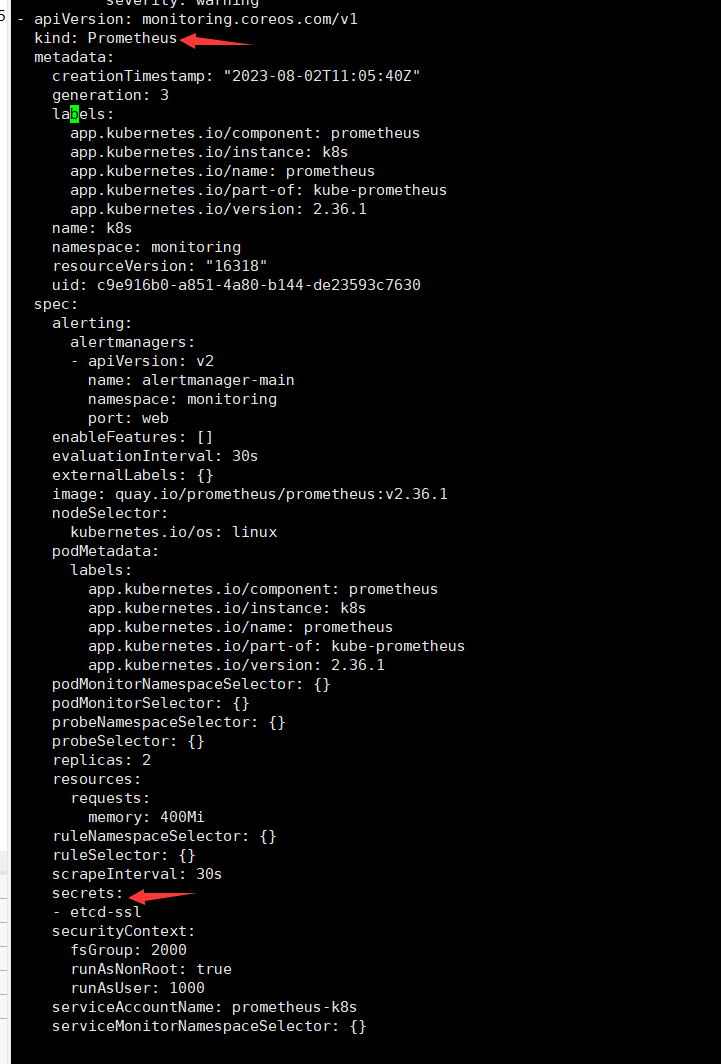
保存退出之后 Prometheus 的 Pod 会自动重启
1
2
3
4
| [root@etcd-2 ~]# kubectl -n monitoring get pod -l app.kubernetes.io/name=prometheus
NAME READY STATUS RESTARTS AGE
prometheus-k8s-0 2/2 Running 0 3m29s
prometheus-k8s-1 2/2 Running 0 3m48s
|
最后 exec 到 pod 里验证查看证书是否挂载。
任意一个 Prometheus 的 Pod 均可验证
1
2
3
4
| [root@etcd-2 ~]# kubectl exec prometheus-k8s-0 -n monitoring -c prometheus -- ls /etc/prometheus/secrets/etcd-ssl
ca
cert
key
|
可以看到,证书挂载成功。
创建 Etcd ServiceMonitor
接下来则是创建一个 ServiceMonitor 对象,让 Prometheus 去采集 etcd 的指标。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| cat > etcd-sm.yaml << EOF
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd
namespace: monitoring
labels:
app: etcd
spec:
jobLabel: k8s-app
endpoints:
- interval: 30s
port: https-metrics #这个 port 对应 etcd-svc 的 spec.ports.name
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-ssl/ca #证书路径
certFile: /etc/prometheus/secrets/etcd-ssl/cert
keyFile: /etc/prometheus/secrets/etcd-ssl/key
insecureSkipVerify: true # 关闭证书校验
selector:
matchLabels:
app: etcd-prom # 跟 etcd-svc 的 lables 保持一致
namespaceSelector:
matchNames:
- kube-system
EOF
|
apply 到 集群里
1
| kubectl -n monitoring apply -f etcd-sm.yaml
|
apply 之后进入 Prometheus 界面,等一会应该就能看到,采集任务里多了一个,就像这样:

配置 Grafana 监控模板
prometheus 配置好后,登陆到 Grafana 平台,添加上 etcd 的监控模版即可。
依次点击“+”号—>Import,之后输入Etcd 的Grafana Dashboard地址。
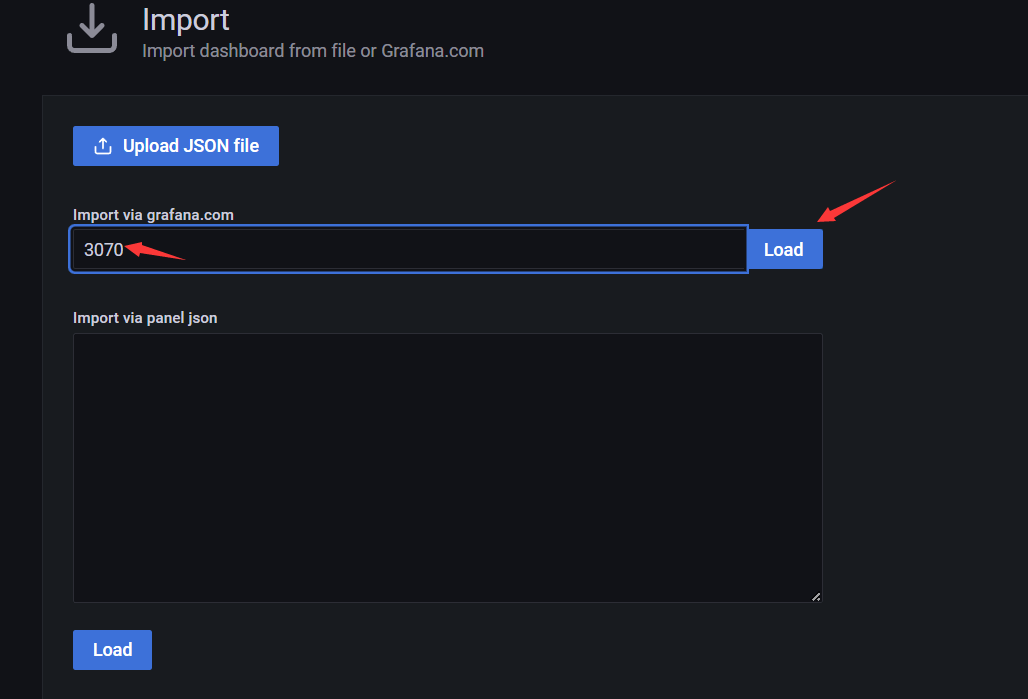
可以填 urlhttps://grafana.com/grafana/dashboards/3070 也可以直接填 id 3070。
导入后就可以看到 etcd 监控了,最终效果如下:
至此,etcd 监控就配置完成了。
3. 配置告警
对于部分核心指标,建议配置到告警规则里,这样出问题时能及时发现。
告警策略
官方策略
Etcd 官方也提供了一个告警规则,点击查看–> etcd3_alert.rules.yml,内容比较多就不贴在这里来了。
以下是基于该文件去除过时指标后的版本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
| # these rules synced manually from https://github.com/etcd-io/etcd/blob/master/Documentation/etcd-mixin/mixin.libsonnet
groups:
- name: etcd
rules:
- alert: etcdInsufficientMembers
annotations:
message: 'etcd cluster "{{ $labels.job }}": insufficient members ({{ $value
}}).'
expr: |
sum(up{job=~".*etcd.*"} == bool 1) by (job) < ((count(up{job=~".*etcd.*"}) by (job) + 1) / 2)
for: 3m
labels:
severity: critical
- alert: etcdNoLeader
annotations:
message: 'etcd cluster "{{ $labels.job }}": member {{ $labels.instance }} has
no leader.'
expr: |
etcd_server_has_leader{job=~".*etcd.*"} == 0
for: 1m
labels:
severity: critical
- alert: etcdHighNumberOfLeaderChanges
annotations:
message: 'etcd cluster "{{ $labels.job }}": instance {{ $labels.instance }}
has seen {{ $value }} leader changes within the last hour.'
expr: |
rate(etcd_server_leader_changes_seen_total{job=~".*etcd.*"}[15m]) > 3
for: 15m
labels:
severity: warning
- alert: etcdHighNumberOfFailedGRPCRequests
annotations:
message: 'etcd cluster "{{ $labels.job }}": {{ $value }}% of requests for {{
$labels.grpc_method }} failed on etcd instance {{ $labels.instance }}.'
expr: |
100 * sum(rate(grpc_server_handled_total{job=~".*etcd.*", grpc_code!="OK"}[5m])) BY (job, instance, grpc_service, grpc_method)
/
sum(rate(grpc_server_handled_total{job=~".*etcd.*"}[5m])) BY (job, instance, grpc_service, grpc_method)
> 1
for: 10m
labels:
severity: warning
- alert: etcdHighNumberOfFailedGRPCRequests
annotations:
message: 'etcd cluster "{{ $labels.job }}": {{ $value }}% of requests for {{
$labels.grpc_method }} failed on etcd instance {{ $labels.instance }}.'
expr: |
100 * sum(rate(grpc_server_handled_total{job=~".*etcd.*", grpc_code!="OK"}[5m])) BY (job, instance, grpc_service, grpc_method)
/
sum(rate(grpc_server_handled_total{job=~".*etcd.*"}[5m])) BY (job, instance, grpc_service, grpc_method)
> 5
for: 5m
labels:
severity: critical
- alert: etcdHighNumberOfFailedProposals
annotations:
message: 'etcd cluster "{{ $labels.job }}": {{ $value }} proposal failures within
the last hour on etcd instance {{ $labels.instance }}.'
expr: |
rate(etcd_server_proposals_failed_total{job=~".*etcd.*"}[15m]) > 5
for: 15m
labels:
severity: warning
- alert: etcdHighFsyncDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile fync durations are
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.5
for: 10m
labels:
severity: warning
- alert: etcdHighCommitDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile commit durations
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.25
for: 10m
labels:
severity: warning
- alert: etcdHighNodeRTTDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": node RTT durations
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99,rate(etcd_network_peer_round_trip_time_seconds_bucket[5m])) > 0.5
for: 10m
labels:
severity: warning
|
核心策略
实际上只需要对前面提到的几个核心指标配置上告警规则即可:
sum(up{job=~".\*etcd.\*"} == bool 1) by (job) < ((count(up{job=~".\*etcd.\*"}) by (job) + 1) / 2) : 当前存活的 etcd 节点数是否小于 (n+1)/2- 集群中存活小于 (n+1)/2 那么整个集群都会不可用
etcd_server_has_leader{job=~".\*etcd.\*"} == 0****:etcd 是否存在 leader- 为 0 则表示不存在 leader,同样整个集群不可用
rate(etcd_server_leader_changes_seen_total{job=~".\*etcd.\*"}[15m]) > 3 : 15 分钟 内集群 leader 切换次数是否超过 3 次histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".\*etcd.\*"}[5m])) > 0.5****:5 分钟内 WAL fsync 调用延迟 p99 大于 500****mshistogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~".\*etcd.\*"}[5m])) > 0.25 ****:5 分钟内 DB fsync 调用延迟 p99 大于 500****mshistogram_quantile(0.99,rate(etcd_network_peer_round_trip_time_seconds_bucket[5m])) > 0.5: 5 分钟内 节点之间 RTT 大于 500 ms
只包含上述指标告警策略的精简版
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| # these rules synced manually from https://github.com/etcd-io/etcd/blob/master/Documentation/etcd-mixin/mixin.libsonnet
groups:
- name: etcd
rules:
- alert: etcdInsufficientMembers
annotations:
message: 'etcd cluster "{{ $labels.job }}": insufficient members ({{ $value
}}).'
expr: |
sum(up{job=~".*etcd.*"} == bool 1) by (job) < ((count(up{job=~".*etcd.*"}) by (job) + 1) / 2)
for: 3m
labels:
severity: critical
- alert: etcdNoLeader
annotations:
message: 'etcd cluster "{{ $labels.job }}": member {{ $labels.instance }} has
no leader.'
expr: |
etcd_server_has_leader{job=~".*etcd.*"} == 0
for: 1m
labels:
severity: critical
- alert: etcdHighFsyncDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile fync durations are
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.5
for: 10m
labels:
severity: warning
- alert: etcdHighCommitDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile commit durations
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.25
for: 10m
labels:
severity: warning
- alert: etcdHighNodeRTTDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": node RTT durations
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99,rate(etcd_network_peer_round_trip_time_seconds_bucket[5m])) > 0.5
for: 10m
labels:
severity: warning
|
配置到 Prometheus
创建 PrometheusRule
使用 PrometheusRule 对象来存储这部分规则。
比较重要的是 label,后续会根据 label 来关联到此告警规则。
这里的 label 和默认生成的内置 PrometheusRule 对象 label 一致,这样就不会影响到其他 rule。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| cat > pr.yaml << "EOF"
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: etcd-rules
namespace: monitoring
spec:
groups:
- name: etcd
rules:
- alert: etcdInsufficientMembers
annotations:
message: 'etcd cluster "{{ $labels.job }}": insufficient members ({{ $value }}).'
expr: |
sum(up{job=~".*etcd.*"} == bool 1) by (job) < ((count(up{job=~".*etcd.*"}) by (job) + 1) / 2)
for: 3m
labels:
severity: critical
- alert: etcdNoLeader
annotations:
message: 'etcd cluster "{{ $labels.job }}": member {{ $labels.instance }} has no leader.'
expr: |
etcd_server_has_leader{job=~".*etcd.*"} == 0
for: 1m
labels:
severity: critical
- alert: etcdHighFsyncDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile fsync durations are {{ $value }}s(normal is < 10ms) on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".*etcd.*"}[5m])) > 0.5
for: 3m
labels:
severity: warning
- alert: etcdHighCommitDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile commit durations {{ $value }}s(normal is < 120ms) on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~".*etcd.*"}[5m])) > 0.25
for: 3m
labels:
severity: warning
- alert: etcdHighNodeRTTDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": node RTT durations {{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket[5m])) > 0.5
for: 3m
labels:
severity: warning
EOF
|
Apply 到集群里
1
| kubectl -n monitoring apply -f pr.yaml
|
配置到 Prometheus
1
| kubectl -n monitoring get prometheus
|
对上述对象进行修改,添加 ruleSelector 字段来通过 label 筛选前面的告警规则。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: example
spec:
serviceAccountName: prometheus
replicas: 2
alerting:
alertmanagers:
- namespace: default
name: alertmanager-example
port: web
serviceMonitorSelector:
matchLabels:
team: frontend
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
ruleNamespaceSelector:
matchLabels:
team: frontend
|
修改完成后,Prometheus 会自动重载配置,不需要重启 Pod,进入 Prometheus rules 界面即可看到新的规则
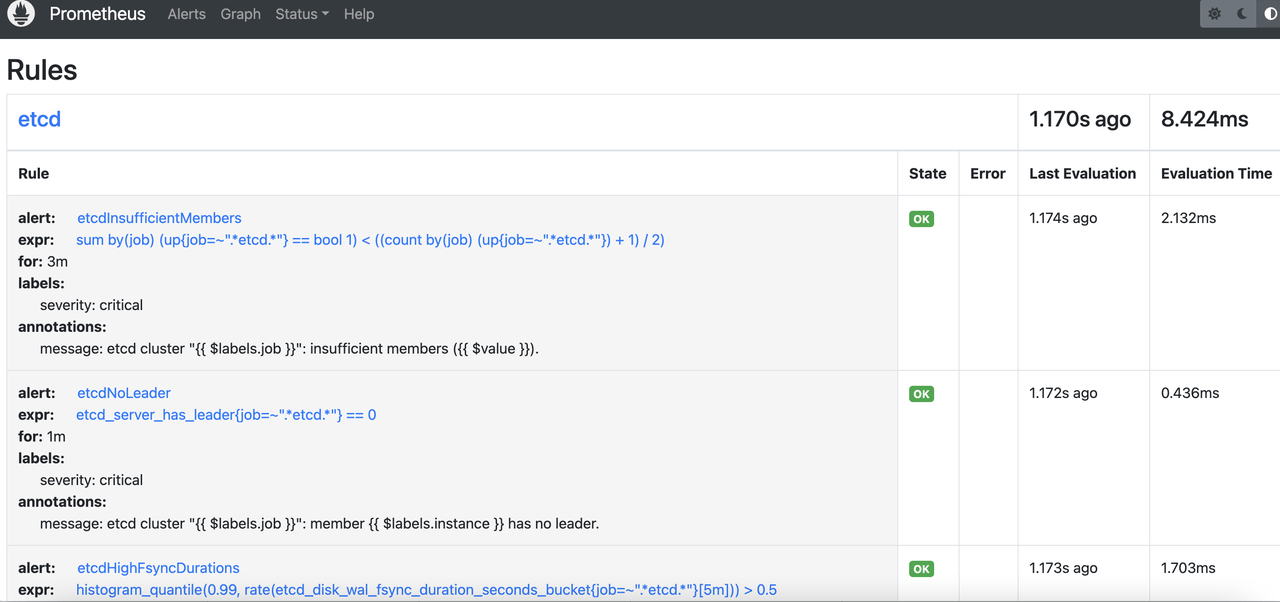
接下来就是配置 AlertManager 了。
配置 AlertManager
默认 AlertManager 就会收到 Prometheus 触发的警告,只需要配置将警告发送到外部系统即可。
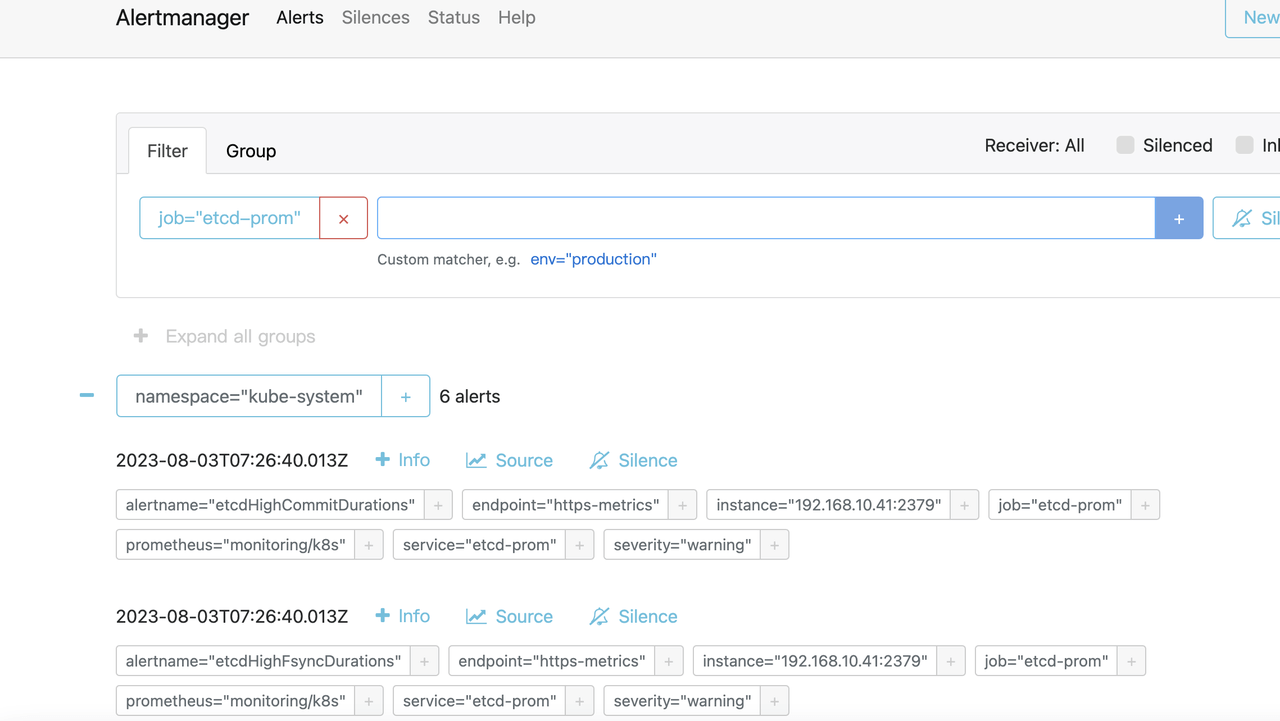
4. 小结
本文主要分享了如何将 etcd 集群接入监控告警,包括三部分内容:
- 1)etcd 的核心指标
- 2)如何接入 Prometheus + Grafana
- 3)如何根据核心指标配置告警规则