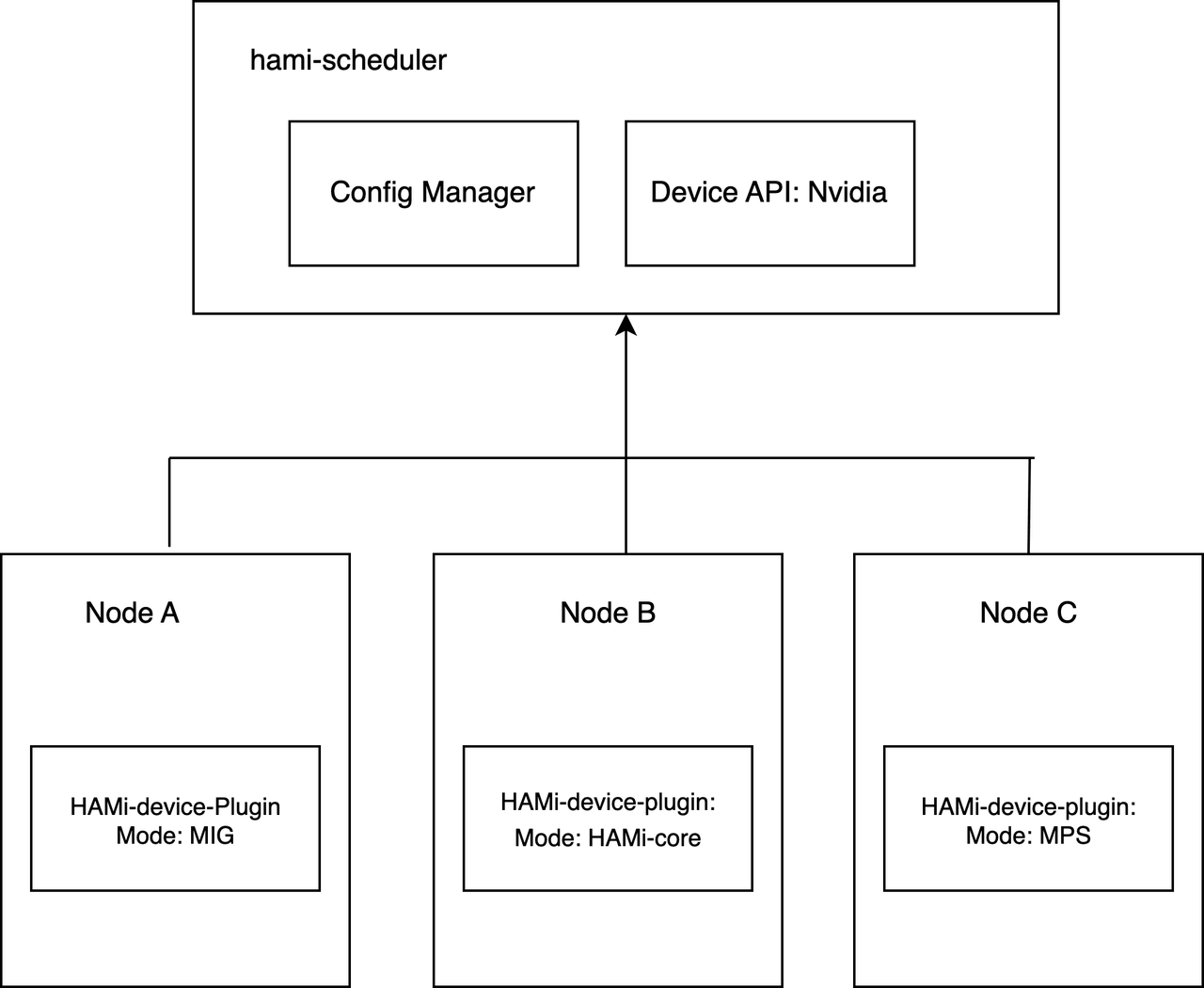
2)hami-device-plugin 以 DaemonSet 方式运行,会在所有(gpu=on标签)节点启动,并在 Pod 启动时会将 libvgpu.so 复制到宿主机 /usr/local/vgpu/ 目录
3)hami-device-plugin 为 Pod 分配 GPU 时会将宿主机 libvgpu.so 文件挂载到 Pod 中
问题就出现在第二步:每次 hami-device-plugin Pod 启动时都会重新将 libvgpu.so 复制到宿主机, GPU Pod 中的 libvgpu.so 文件是通过 bind mount 挂载进去的,因此操作宿主机上的 libvgpu.so 文件是可能会对正在运行的 GPU Pod 造成影响的。
#!/bin/sh
# Check if the destination directory is provided as an argumentif[ -z "$1"];thenecho"Usage: $0 <destination_directory>"exit1fi# Source directorySOURCE_DIR="/k8s-vgpu/lib/nvidia/"# Destination directory from the argumentDEST_DIR="$1"# Check if the destination directory exists, create it if it doesn'tif[ ! -d "$DEST_DIR"];then mkdir -p "$DEST_DIR"fi# Traverse all files in the source directoryfind "$SOURCE_DIR" -type f |whileread -r source_file;do# Get the relative path of the source filerelative_path="${source_file#$SOURCE_DIR}"# Construct the destination file pathdest_file="$DEST_DIR$relative_path"# If the destination file doesn't exist, copy the source fileif[ ! -f "$dest_file"];then# Create the parent directory of the destination file if it doesn't exist mkdir -p "$(dirname "$dest_file")"# Copy the file from source to destination cp "$source_file""$dest_file"echo"Copied: $source_file -> $dest_file"else# Compare MD5 values of source and destination filessource_md5=$(md5sum "$source_file"| cut -d ' ' -f 1)dest_md5=$(md5sum "$dest_file"| cut -d ' ' -f 1)# If MD5 values are different, copy the fileif["$source_md5" !="$dest_md5"];then cp "$source_file""$dest_file"echo"Copied: $source_file -> $dest_file"elseecho"Skipped (same MD5): $source_file"fifidone
主要就是做 MD5 验证,仅 MD5 不一致时才会执行 cp 操作进行写入。
1
2
3
4
5
6
7
# If MD5 values are different, copy the fileif["$source_md5" !="$dest_md5"];then cp "$source_file""$dest_file"echo"Copied: $source_file -> $dest_file"elseecho"Skipped (same MD5): $source_file"fi
同时还做了一个优化,libvgpu.so 新增了一个 version 后缀,变成了 libvgpu.so.2.5.0 这种,这样多版本 libvgpu.so 不会互相影响。
// GetLibPath returns the path to the vGPU library.funcGetLibPath()string{libPath:=hostHookPath+"/vgpu/libvgpu.so."+info.GetVersion()if_,err:=os.Stat(libPath);os.IsNotExist(err){libPath=hostHookPath+"/vgpu/libvgpu.so"}returnlibPath}
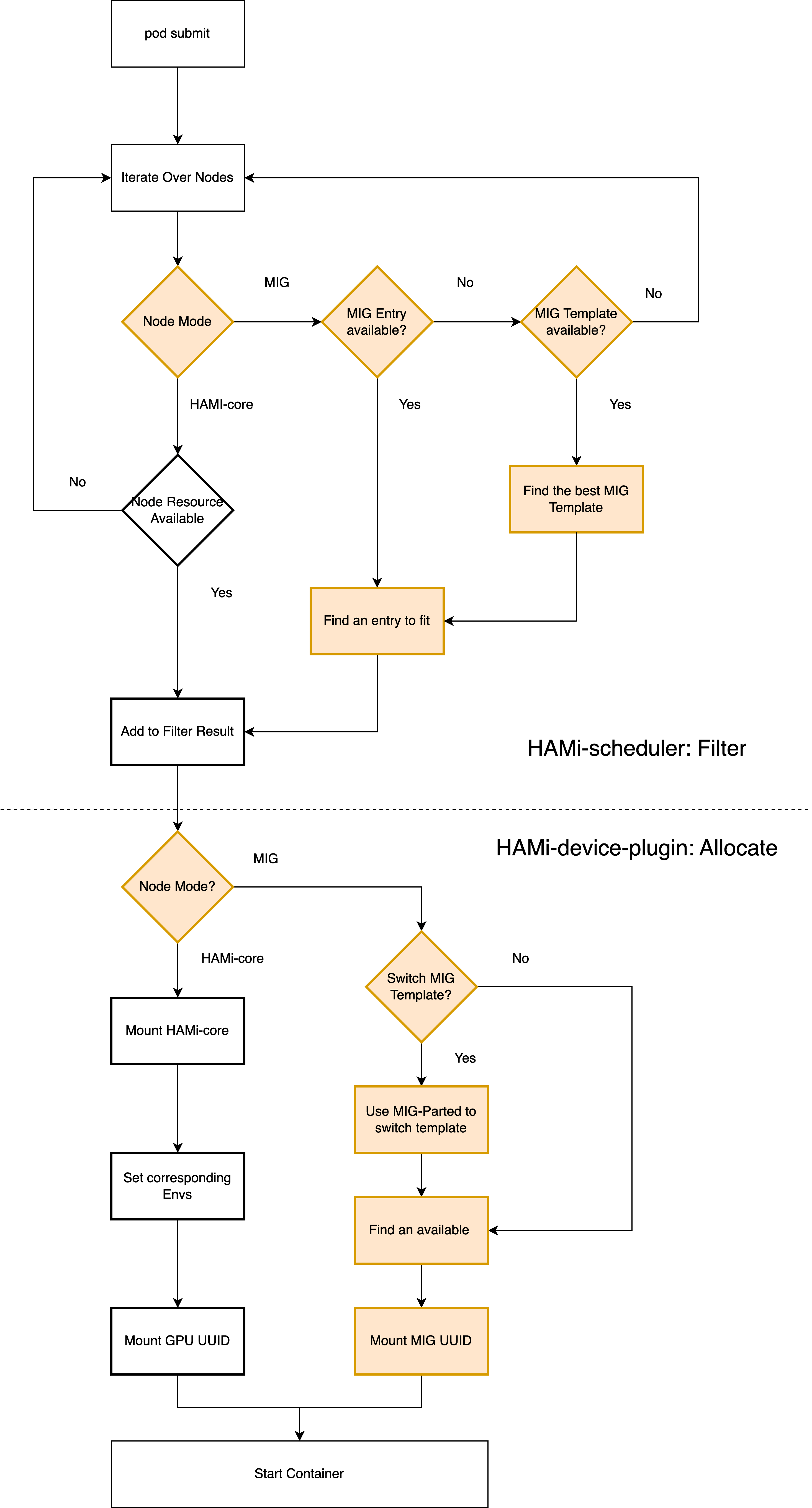
apiVersion:v1kind:Podmetadata:name:gpu-podannotations:nvidia.com/vgpu-mode:"mig"#(Optional), if not set, this pod can be assigned to a MIG instance or a hami-core instancespec:containers:- name:ubuntu-containerimage:ubuntu:18.04command:["bash","-c","sleep 86400"]resources:limits:nvidia.com/gpu:2nvidia.com/gpumem:8000
# HELP nodeGPUMigInstance GPU Sharing mode. 0 for hami-core, 1 for mig, 2 for mps# TYPE nodeGPUMigInstance gaugenodeGPUMigInstance{deviceidx="0",deviceuuid="GPU-936619fc-f6a1-74a8-0bc6-ecf6b3269313",migname="3g.20gb-0",nodeid="aio-node15",zone="vGPU"}1nodeGPUMigInstance{deviceidx="0",deviceuuid="GPU-936619fc-f6a1-74a8-0bc6-ecf6b3269313",migname="3g.20gb-1",nodeid="aio-node15",zone="vGPU"}0nodeGPUMigInstance{deviceidx="1",deviceuuid="GPU-30f90f49-43ab-0a78-bf5c-93ed41ef2da2",migname="3g.20gb-0",nodeid="aio-node15",zone="vGPU"}1nodeGPUMigInstance{deviceidx="1",deviceuuid="GPU-30f90f49-43ab-0a78-bf5c-93ed41ef2da2",migname="3g.20gb-1",nodeid="aio-node15",zone="vGPU"}1